
Some URLs which are “technically valid” URLs do not work properly within EuroGA.
This is due to the way the text is parsed to create clickable links while rejecting potentially malicious code.
One example are the complex URLs produced by Google Translate which contain “www” potentially more than once within the URL.
It may be changed one day but for now the simplest solution is to use e.g. tinyurl.com to convert such a URL into a simple URL.
URLs which end with a punctuation character
To create a link with one of those, insert the whole thing in square brackets – example here of a URL ending with a minus sign
It’s bad practice to have such URLs but some people do create them…
There is another issue with some weird URLs which is difficult to address.
It’s the /_ character pair, followed by another underscore further down the URL.
Fundamentally there is a conflict in the textile language specification here and the “auto linking” feature. It’s probably impossible for the system to know what’s intended and implementing something which fixed this would almost certainly break something else, because in other circumstances you’d want it to behave differently. One solution is to use the entity number for the underscore, which is 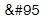 Just replace one of the underscores with that and it’ll look right and the link will work properly, like this:
Just replace one of the underscores with that and it’ll look right and the link will work properly, like this:
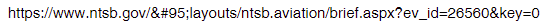
Another is to stick these weird URLs into one of the shorteners like TinyURL… OTOH a lot of people hate these because they can’t see what they are about to click on 
There are no weird URLs. There are valid and non-valid ones. One way to check their validity is a regular expression. Ruby on Rails supports regular expressions.
The issue is not there; it is to do with looking for other patterns such as underline specifications, which can appear within URLs.
Most often, the solution is to make the URL a clickable link e.g.
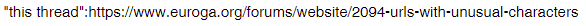
will produce
These also look much neater.
Another thing which is worth a mention is that people often paste in huge long URLs, often with FB stuff on the end e.g. in this
the whole &fbclid=IwAR3IIysssxunR8H40VwcNbKSTJI_1rZhHqi187vBERw5RXB2_CYkAAl8EA0 is pointless.
Another one came up today. This youtube URL has two successive hyphens
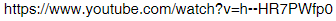
and the forum text processor replaces them with a long hyphen.
Obviously the correct solution would be to rearrange the order of text processing, so potential URLs are identified before any other processing, but that will break some other stuff where a URL-like piece of text was entered. So whichever way one does that, it will affect something, and it will be expensive to look at.
However the < pre > method solves it:
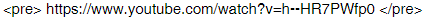
Another thing, not related to URLs but worth a mention while I am here, is that some people are incorrectly entering hyphens. You must have a space around any hyphen. Well, that is gramatically obvious but not always easy on say a phone… If you do not have the space before it and a space after it, you are creating crossed out text

which looks like this
and I fix a lot of posts with that in

