Is there a way to scan e.g. an article to pdf to have both pictures and searchable text? I can scan to image (no text recognition), or to plain text OCR (no images), but not both. An example with both a photo and highlightable text.
Edit: something like this from Adobe, but free:
Capitaine wrote:
Edit: something like this from Adobe, but free
In my experience, you get what you pay for.
Can’t vouch for the following, but I downloaded the demo and tried it on a random PDF, and it appeared to do what you are looking for. It isn’t free, and the interface is unlikely to win any awards, but it is apparently based on an open source OCR engine (possibly Tesseract, but not certain of this). I didn’t look into it further, but possibly you could find a command line tool for the open source engine and use it for free that way.
It says it is available for Mac and Windows. I tried in on Mac at OCRKit
Not sure of the requirements here, but recent OS versions on iPhones and Macs do OCR on any image or photo: https://support.apple.com/en-us/HT212630
I used to be really annoyed at being sent screenshots with snippets of text relevant to some discussion instead of the sender just simply pasting the text on the email. Now I just copy the text right from the pixels, real nice timesaver. ( while still grumbling about the stupidity of sending screenshots to capture a few lines of text…)
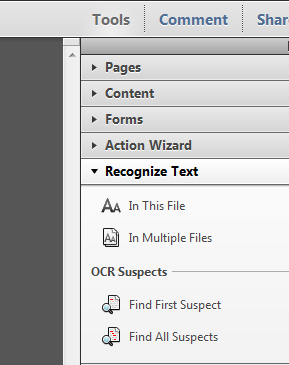
I have normally done that by scanning the page(s) direct to a PDF file (or just scanned the page(s) to jpegs and then created a PDF with them, 1 per page) and then opening the PDF in Adobe Acrobat and using the OCR feature.
The result is your original PDF with graphics pages (which is normally what you do want, since OCR is not perfect, especially with symbols like °C) but which is text-searchable (with some care like avoiding searching for ° symbols).
I am not aware of any tool which will create a decent PDF from images i.e. the sort of PDF you would get if you created a document using MS Word, did the graphics using the MS Word graphics functions (which are pretty primitive for such a widely used text editor) and then an Export to PDF. That would require a lot of intelligence, and perfect OCR.
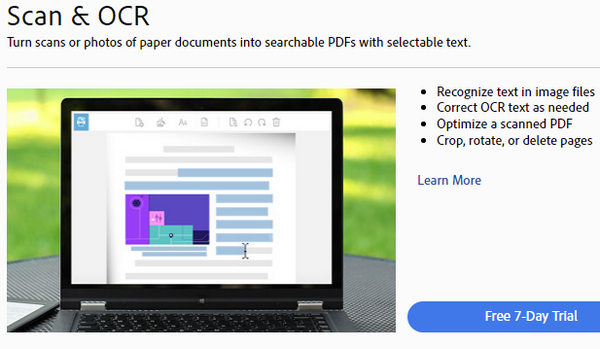
The thing I don’t know off hand is whether the free Adobe PDF Reader can do OCR. The free reader does more and more with each version. I have just looked at Acrobat X PRO (which I am fairly sure is the free one) and see this
AFAIK Adobe is adopting the rental model, which professional photographers love (Lightroom etc) and everybody else hates 
Peter wrote:
I have just looked at Acrobat X PRO (which I am fairly sure is the free one)
Doesn’t look like the free one to me. PRO looks like the most expensive one (~ £20 / MONTH) and according to the feature set the only one to “Turn scanned paper documents into searchable and editable PDFs”
derek wrote:
Doesn’t look like the free one to me. PRO looks like the most expensive one (~ £20 / MONTH) and according to the feature set the only one to “Turn scanned paper documents into searchable and editable PDFs”
There’s one more handy feature in it – modifying PDF files. Some people think it can’t be done. Agree it’s expensive.
I’d be happy to hear about another batch OCR solution with document language recognition. I scan everything I can and then shred it. The scanner uploads to a folder on which I run Acrobat OCR periodically. It’s great for finding stuff later.
Interesting… no idea where this installation came from. Definitely not a rented version, but probably some years old. I normally buy software but then use it for many years (still use a PCB design prog from 1995).
Yes you can edit PDFs but only a subset of them. Many reasons e.g. a PDF could contain the literal text (with a fontspec and a x,y position spec for each line; the classic way to do a simple PDF… I used to write code to do that on a Z80 in the 1980s) or it could specify and x,y position each letter individually (realising this is “text” then needs a lot more intelligence; this method arrived many years ago in the DTP / typesetting sphere where precision was desired, and you could shift individual chars up/down) and various variations of this.
Check out https://www.pdf-xchange.com/
Edit: I sound like annoying Amazon advertising, but for real, that’s my most used program at work.
Aha! Found a free one: https://tools.pdf24.org/en/ocr-pdf. My first attempt in the F-PBIR thread which worked with searchable text.
Thanks for the ideas, and especially dublinpilot for the offer of help.